





▲有时,哪怕只有一丁点像素瑕疵,人工智能也会在图片识别中产生错误。要纠正这个纰漏,科学家们还有很长的路要走。
人工智能(AI)的“所见”会影响它的“所思”吗?
为了回答这个问题,科学家们进行了很多实验。比如,让人工智能车“看”路况,或者给信号灯贴黑胶带。结果表明,在路上,人工智能常因“看不清”物体而造成路况误判;信号灯一干扰,人工智能就成了“瞪眼瞎”。
如果这些“漏洞”被黑客们利用,那可是致命威胁。随着人工智能应用广泛走入生活,这必须引起重视。
“海龟来福枪”事件暴露图像识别短板
人类一眼就能看出来的潦草数字,机器识别若干次都错了。而且,只要掌握改动图像的方法,就能使人工智能系统产生误判。比如,研究者就曾让AI将一只海龟误认作来福枪。
苹果和亚马逊的人工智能产品SIRI和Alexa都可以识别声音,脸书的人工智能产品可以识别人脸或照片上的物体,其他诸如人工智能在线客服等应用也已相当普遍。比如,谷歌的子公司Waymo甚至在美国亚利桑那州凤凰城的郊区试运行了一项基于人工智能技术的自动驾驶出租车服务。
六年前,还在加拿大蒙特利尔大学攻读博士学位的伊恩·古德费尔就隐约感到人工智能存在漏洞。当时,一位名为克里斯蒂安的谷歌工程师手写了一组数字,让人工智能系统来识别。尽管他的字迹比较凌乱,但人类一眼就能认出来。可实验中,机器识别了若干次,竟然都错了。
当时,古德费尔以为,纠正这些漏洞应该是很容易的事,可事实并非如此。
发生在2017年末的“海龟来福枪”事件,引起了业界的广泛关注。美国麻省理工学院的阿尼什·阿特莱雅和他的同事让人工智能系统去识别一只海龟。他们从不同角度拍摄海龟照片,并改变海龟背壳上的图案。最终,人工智能系统未能正确识别海龟模型图,将之误认为是来福枪。
此后,利用人工智能视觉识别缺陷攻击系统的案件接连发生。比如,几个月前,在某停车场,一辆配备了人工智能系统的无人驾驶车因无法识别车前的物体,继续行驶,以至酿成车祸。
对此,如今已是苹果公司机器学习研究院工程师的古德费尔忧心忡忡。意大利卡利亚里大学的贝提西塔·比吉欧博士坦言,将这种黑客技术商业化只是时间问题。要知道,有志于开发此类黑客技术以牟利的人不在少数。
阿特莱雅和他研究团队已经证明,就算是不精通人工智能技术的人,也可以组织起蓄意攻击。研究人员们把假想的攻击目标定为谷歌的人工智能图片识别工具(伦敦动物学会正使用这一服务来识别被照相机拍到的濒危动物)。研究人员并不知道算法是如何分析图片的,但是他们记录下了算法对一系列测试图片的输出结果。
“我们做的只是输入一张图片,看看输出结果是什么。”阿特莱雅说。起初,研究人员们输入了一张狗的照片,人工智能成功识别了出来。接下来,研究人员逐渐调整图片。最后,图片被调整到从人眼看起来就像是站在雪地上的两名滑雪者,即使图片被改动到了这种地步,算法还是能给出正确的答案。
也就是说,用这种方法,通过反复试验,研究人员总能找到可以让人工智能产生误判的某张图片——这对一个掌握基础软件知识的人来说并不难。
算法天然“漏洞”给黑客可乘之机
人工智能并不能像我们的大脑一样重现出事物本来的样子,它只是基于一堆像素的关键信息分析来推断结果。
利用这一点,心怀不轨之人就可能恶意操纵人工智能技术来实现其阴暗企图。
为何会发生这样的被“黑”事件?那是因为人工智能系统在识别图像时,看到的只是像素。“与人类大脑不同,人工智能看不到事物的整体。”一位神经科学家解释说。
如果了解这一工作原理,那么只需要一点点小改变,就可以让人工智能系统把图片认错。这同样也适用于文本、语音或视频技术。曾经有个团队就“黑”掉了某款语音转文字的工具,让它记录了一堆根本不存在的指令。
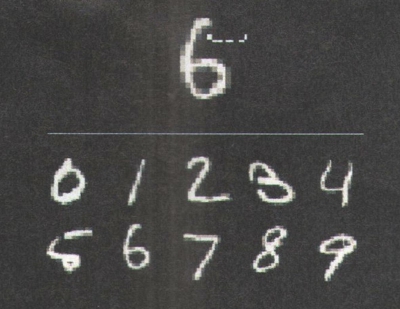
▲科学家进行了一项实验,让人工智能识别潦草的数字。你能猜到人工智能将数字“6”认成了黑板横线下方的哪个数字吗?没错,就是横线下左侧第二行第一个的“5”。在实验中,大多数人都猜对了。所以说,其实人脑和机器脑之间存在着某种共通之处。
如此尖端前沿的人工智能技术,为什么会犯下这样低级的错误?要弄清这个问题,我们不妨来回顾一下人工智能的诞生历史。
机器学习是现在用得最广泛的人工智能技术之一。几十年前,科学家们发明这一技术的初衷是想让机器能够理解概念,比如让机器理解什么是鼻子、什么是眼睛。但事实证明,这似乎不可能。
此后,深度学习神经网络算法诞生了。这一算法模拟了人脑的神经网络,设置了一层又一层的输入、输出数据连接,通过大量数据在网络中的运算、分析,即可输出一定的结果。
举例来说,科学家们将大量某人休假的照片、停车标志图标或者演讲范本输入到神经网络中,那么神经网络即使不理解“人脸”“停车标志”或者很多字词的含义,也能从大数据中抽提出数据模型,于是它就具备了一定的识别能力,并可对后续识别出的内容做出回应。
然而,利用这一点,心怀不轨之人就可能恶意操纵人工智能技术,来实现其阴暗企图。
英国科技企业Onfido近几年成长迅速,其核心业务就是对照片中的人物进行识别,进而帮助雇主对某些特定人物进行背景调查。比如,求职者们会被应聘公司要求将自己的自拍照、驾照或护照上传到Onfido的人工智能系统中。接下来,系统会对他们的信息进行交叉比对和分析。假设有一位国外求职者想在英国的某企业谋得一个差事,可他并没有工作签证,那么这位外国求职者就可以请某位黑客帮忙,将他护照上的照片微调一下,让人工智能系统将其误认为某位英国公民。虽然这只是一种推想,但Onfido公司已高度重视此类潜在的攻击。
但实际上,除了识别图像外,人工智能系统还需要核实其他身份证件信息,因此一般人想要骗过人工智能并非易事。
此外,Onfido也禁止外来人员访问其代码,这就基本杜绝了让外人发现其系统工作机制的可能。该公司副总裁莫汉·马哈德凡表示,公司在核心的机器学习算法周围,布置了一个强有力的防火墙,当危机真的发生时,至少会触发警报。
然而,这并不意味着人工智能算法就能免受蓄意攻击的侵害。电脑黑客们如能找到有效破解防火墙的办法,那他们就能找到突破口。事实上,这类技术就和传统的电脑黑客没什么差别。
科技巨头们也已经意识到了问题,并开始布局反黑客技术。2018年4月,IBM发布了一款工具箱,以帮助人工智能研究员们找到抵御黑客的方法。这个工具箱里有用于制造对抗训练图片的算法、神经网络对黑客进行反击的测量方法等工具。
只有更接近人脑AI才会更安全
人脑在后阶段的视觉信息处理过程中,会有更多神经元不断将信号传递给最初参与感知的神经元,直到做出正确决定。
因此,只有更接近人脑,才可能实现更高程度的人工智能。遗憾的是,目前,我们对人脑的工作机制所知甚少。
目前我们能做的事还相当有限。比吉欧表示,即便能把人工智能算法调整到让它对像素中的微小变化不那么敏感,或者拒绝一些有明显变化的样本,这仍然治标不治本。这些方法只能让识别结果提高百分之几的准确率,但系统本身仍易受攻击。古德费尔则认为,这些问题正促使我们重新思考人工智能的框架设计。

事实上,就算是人的神经网络也会出错。2018年,古德费尔和同事们做了一个实验。首先,研究人员们以极快的速度向人类展示一组高清图片,并让他们从诸多选项中选择一个来描述图片内容。通常来说,人能很快做出正确选择。接着,研究人员对把图像的画质调低。此时,如果给人类足够的时间思考,他们还是能做出正确的选择。反之,如果加快看图速度,那么人也会出现识别错误。
虽然他们的研究样本只有38人,但这也反映出一个事实——在某些情况下,人眼也可能像人工智能一样被欺骗。后来,更大样本的研究也证实了这一结论。
为什么会这样呢?古德费尔认为,人眼识别物体是分几个步骤完成的:在最初的几十毫秒内,人类的感知是由单向传递信息的神经元主管的,这和人工神经网络的运作方式相似。但人脑在后阶段的信息处理过程中,会有其他神经元参与感知反馈,这些神经元不断修正信息,直到做出正确识别。
“大脑中深层的神经元会将信号传递给最初参与感知的那些神经元,并不断更新信号,直到做出正确决定。”古德费尔说。现在的人工智能算法显然不具备这种能力。
美国马里兰州约翰霍普金斯大学的认知科学家查兹·费尔斯通也认为,人类的视觉感觉可被分割成几部分,其中有些部分的信息处理方式与人工神经网络差异不大。
能不能让人工智能也来学习人脑神经网络的工作方式呢?或许这样就可以帮助人工智能彻底避免黑客攻击。
美国纽约大学的心理学家盖里·马库斯是这一理论的拥趸。他认为,人工智能漏洞恰恰“很好地说明了深度学习算法没什么用”,要实现更高能的人工智能,必须让人工智能更像人脑。遗憾的是,目前我们对人脑的工作机制所知甚少。
也许目前可以采取一些折中的办法:就算人工智能不知道自己看到的是什么,也可以将更多常识应用到图像识别中去。麻省理工学院的神经科学家吉姆·迪卡洛表示:“我们应找到让人工智能更加自信的方法。”比如说,如果根据大多数像素的分析结果,人工智能认为某个图像是一条狗,那么就算有少数像素并不与狗的模型相匹配,也应该不会影响它做出最终判断。
另一个可能的解决方法,是让人工智能去分析更多的特征指标:有眼睛吗?有鼻子吗?有毛发或者尾巴吗?这样一来,一些不符合模型设定的像素点就被自动“无视”了。但目前的技术水平还无法实现这一点。
不过任何尝试都是值得的。毕竟,攻击人工智能来控制车辆是一回事,“黑”掉人工智能去控制武器又是另一回事。我们必须做好准备。
>>>相关链接:
屠可伟:今天的试错正是为了明天的安全
随着人工智能从实验室走向实际应用,安全性必然成为焦点。
与很多技术与产品一样,实验室阶段更多关注的是理论上的“做成”,即在限定的实验室场景下达到较高的性能。但在实际应用中,场景千变万化,甚至存在人为恶意误导系统的可能性。因此对系统准确性和可靠性的要求变得极高,尤其在诸如无人驾驶这样的应用中,哪怕一次小小的失误,都可能危及生命。
从几年前开始,科学家已着手努力提升人工智能系统的可靠性。近年来,对抗训练成为一个研究热点。科研人员通过精巧的手段,让人工智能系统犯下种种在人类看来十分愚蠢的错误。比如,对图像做出肉眼难以察觉的像素改动,让计算机视觉系统错误识别图中的物体;或者在一段文字中加入一句与主题无关的叙述,让机器阅读系统给出错误的回答等。之所以这么做,恰恰是为了通过“对抗”,对人工智能系统进行额外的训练和算法上的改进,使它们在真正为大众服务时,降低再犯同样错误的概率。
当然,人工智能系统不可能穷尽所有的图像,即使用了上述技术,也不可能让系统完全了解自己可能会犯的所有错误。这就像人在积累了经验之后,依然会犯很多超出经验范畴的错误。但是人类的高明之处在于,面临一项任务时,并不会仅仅依赖于过去执行该任务的经验,而是会综合自己所掌握的相关知识与经验。
人工智能系统要达到这一水准还有很长的路要走。比如,现在大部分人工智能视觉系统算法相对简单,一般只依赖于图像像素进行视觉分析。但如果能做到强人工智能,让其他系统模块参与到视觉识别中来,例如利用常识来帮助视觉做预测,就可大大提升系统的准确性和可靠性。这涉及到人工智能很多不同领域和流派的交叉。而要将不同流派的思想整合到一个系统中,难度相当大,而这也正是当前的一个研究热点。
不过,只要有需求存在,再困难的技术也有可能被突破。我们有理由相信,未来人工智能会越来越安全。但我们也要有心理准备:作为普通人,在享受新技术带来的便利时,尽量不要做太冒险的事,将风险控制在一定范围内。这就像电脑病毒,尽管带来很多安全风险,但有了专业人士孜孜不倦的防控和大众不断提高的安全意识,电脑病毒并没有阻止计算机和网络的普及。
相信今天的试错,会使明天即将融入我们生活的人工智能更加安全可靠。(作者为上海科技大学助理教授)
作者:金小莫编译
编辑:朱颖婕
责任编辑:樊丽萍
*文汇独家稿件,转载请注明出处。
违法与不良信息举报电话:021-22898778
本网站文字、图片和视频作品,除特别说明外均为独家授权发布,转载请注明出处和原文链接。