



只有解决好目前中文字符集存在的种种问题,我们的历史文献才能在数字媒体上不打折扣地讲述真正的中国故事。而字符集问题的解决,对于当前相关专业领域来说,并非极其繁难之事。
中国传统文化的基本载体是历史文献,只有通过这些第一手文献的阅读,人们才能接触真实的传统文化。然而,受限于中文字符集建设的发展水平,我们的历史文献在当下主流信息传播平台上存在话语障碍,主要表现为三方面的问题。
“一字多码”,使得传统文化的数字传播与利用受损
电脑字符集中的每个字符,都应该只有一个唯一编码,才能被进行有效的数字处理。但是,现在的电脑通用字符集中有不少文字单位与码位不唯一对应的情况。这一问题,主要是由于在中日韩联合进行字符集编码过程中、各家都希望自己的习用字形尽可能充分进入字符集而造成的。这些字,多为历史文献中的常用字,且往往是不容易区分彼此的构形微别字,如“户”、“戶”与“戸”,“宫”与“宮”。这种构形微别字同构形差异明显的异体字、繁简字不同,后二者如“铺(内码8216)”与“舗(内码8217)”,“汇(5F59)”与“彚(5F5A)”,由于构形上存在明显差异,在输入时很容易被区分开来;而构形微别字在输入过程中,因为有这种一字多码的输入源,很容易导致同字却使用不同内码字的情况。由此,人们在网络或相关数据库查找文献时,就会出现以下情况:该找到的找不到,该搜齐的搜不齐,而查找搜索者却误以为这就是真实检索结果,传统文化宝藏的利用无形中被打了折扣。如“文渊阁四库全书”(“Complete Library in Four Branchesof Literature”),是一个非常注重区别异体字、反映文献原貌的电子古籍检索系统,但也不免因同字多码问题而导致全文检索的失误。如“彝(5F5D)”,另有三个不同编码而同字者:彛(5F5B)、彜(5F5C)、彞(5F5E)。如果全文检索“彝(5F5D)”,匹配的结果是32041个,但是用另外三个字形彛(5F5B)、彜(5F5C)、彞(5F5E)去全文检索,匹配项却只有22054,也就是说,文献检索范围内另有9987个“彝”的文例失检。再如在“国学大师”网上检索“户”,得到93349个检索结果,而输入“戸”,则只有24046个检索结果。
而尤当引起注意的是,即使在目前最通用的GBK字符集中,类似的同字多码者也很多,除了上举一字四码者外,一字三码的情况如:
娱(5A1B)娯(5A2F)娱(5A31)
揺(63FA)搖(6416)摇(6447)
吳(5433)吴(5434)呉(5449)
奨(5968)奬(596C)獎(734E)
户(6236)户(6237)戸(6238)
挿(633F)插(63D2)揷(63F7)
一字二码的数量更加可观:
捏(634F)揑(63D1);
尙(5C19)尚(5C1A);
尓(5C13)尔(5C14);
尪(5C2A)尫(5C2B);
捜(635C)搜(641C);
尶(5C36)尴(5C37);
寜(5BDC)寧(5BE7);
帯(5E2F)带(5E36);
掲(63B2)揭(63ED);
宫(5BAB)宮(5BAE);
孳(5B73)孶(5B76);
悳(60B3)惪(60EA);
悞(609E)悮(60AE);
愼(613C)慎(614E);
悅(6085)悦(60A6);
恵(6075)惠(60E0);
徴(5FB4)徵(5FB5);
徳(5FB3)德(5FB7)……
仅以上并不完整的整理,所得多码字共计432个,这已经占了字符集的相当比例。可想而知,通过这样一个字符集进行传统文献的数字传播和阅读,不注意一字多码问题的把控,是很难充分利用文献且保证文献不被误读漏检的。
编码汉字的使用受限于现有技术,使得传统文献的网络阅读失真
目前在通用电脑字符集中已编码汉字的总数已达74588个,但是除了核心部分GBK的20902字外,CJK扩展集的5万多字在数据库中并不能用,无法实现检索、查询、统计等各种处理;而GBK的20902个字和扩展A的6582个字以外的编码汉字无法实现上网查询。
比如在网上查找“(图1)”字(《集韵》“色入切,木茂貌”),而获得的检索结果却是“穑”等一些毫不相干的字。造成这种情况的原因很简单:虽然很多汉字已经编码,在字符集的国际标准中有了合法地位,但是现在的电脑程序系统却并不跟进这种字符集标准的发展,因而造成绝大多数编码汉字不被兼容。编码字遭受网络排斥的结果,就是检索查找的对象被张冠李戴,传统文献的网络阅读失真或意义错失。理论上说,这个问题应该是可以随着电脑技术和标准的完善得到解决的,但事实上,改变这种状况。目前还不在我们的能力范围内。根本原因是,电脑技术是一种受国际标准严格制约的技术,而主导这种技术的乃是微软等少数国际技术垄断企业。新的字符集标准虽然已经出台,但这些企业却能决定世界上各个电脑终端是否采用这种标准。跟进这种新字符集标准需要的投入,相比其受众面窄而必然导致的微小产出,决定了企业目前不会去采取行动。这就是目前数据库、互联网不支持占编码汉字绝大部分的扩展字符集的根本原因。特别要引起注意的是,已经正式在国际标准字符集中获得合法地位的汉字,竟有70%以上还在遭受这种“不公正待遇”,这对我国传统文化的数字传播造成的负面影响是难以估量的。
古文字编码缺位,使最具历史厚度的传统文化资源成为网络传播盲区
目前国际标准电脑字符集中已经编码的汉字,或者说通用字符集中已有的汉字,相对汉字发展史上原有的汉字,有着巨大的覆盖盲区。处于盲区的汉字,无法在通用的电脑终端、手机上获得处理。这种情况,在古文字文献中表现得尤为突出。
以《新甲骨文编》(修订本)为例,该书正编2268字,其中796字是集外字:
挨僾賹譺谙啽埯抝墺仈坺覇佰薭舨捠谤襃賲藵靤虣喺偝惫辈愂誖崩埲逬偪柀胇觱藊覍缏辪杓褾摈擯冫梹僠撥侼舶蔔捕勏乲惭蠺賶乽拆勑谗缠产谄讇椙腸……
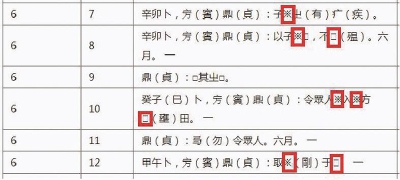
而该书附录的1224字目全属集外字,即全部3492字目中属集外字的有2020个。据此可以大致判断,甲骨文中的集外字约占60%。甲骨文如此,其他类型古文字文献也存在类似情况。字符的大片缺位,导致大批珍贵古文字文献的网络阅读无法真正实现。目前传世文献,已经基本可以实现网络检索,而出土古文字文献则基本处于网络资源的盲区,我们若依靠网络来阅读、检索甲骨卜辞,结果会令人遗憾:比如在“国学大师”网查《甲骨文合集》第六片,即会发现8个集外字开了天窗(上图框红者)。
很显然,只有解决好上述种种字符集问题,我们的历史文献才能在数字媒体上不打折扣地讲述真正的中国故事。而字符集问题的解决,对于当前相关专业领域来说,并非极其繁难之事。主要的问题是,我们需要认识到此事的重要性,开始积极采取措施。在这方面,政府的顶层设计和政策引导会起到关键作用。
当然,问题的具体解决,还需要区别情况分别对待。首先,对“一字多码”问题,可以开发针对性的输入法,用提示多码字的方式来帮助输入者规避不当文字输入,实现各内码字同传统文献的精准对应;在网络数据库检索的环节,则可以通过开发有效的同字多码认同程序来保证检索数据的准确性。
其次,对第二类问题,即扩展字符的网络和数据库使用障碍问题,针对性的程序开发是解决问题的良策。
对于第三类问题,即如何补充字符集缺口,问题会复杂一些。事实上,汉字古文字在国际标准字符集中的编码,在中国的推动下,于本世纪初即已开始,但因为是在相关国际标准化组织框架下运作,遇到了不少问题,至今并没有实质性进展。鉴于这种情况,我们不妨先走国标路线,即先为中国历史文献的集外字实现中国标准的统一编码,在情况允许时,再使之与国际标准对接。目前,相关研究领域都是采用字体技术来应对这一难题,其要点就是利用通用GBK字符集中古文字文献用不到的字符码位,来填入该字符集本不包含的那些集外字,以“雀占鸠巢”的方式,来构建一个对应古文字文献用字的新字符集。这方面,如华东师范大学中国文字研究与应用中心开发的新版“文字网”古文字文献数字平台,就对集外字的编码与检索做了统一标准的有效尝试,实现了已公布古文字文献的全面整理与全部文献用字的检索显示,取得了较为丰富的经验。该“文字网”系列古文字文献数据库分别为甲骨文、金文、楚简、秦简等数据库配备专门字体,对于全球所有电脑终端来说,只要下载这些字体,数据库的使用就可以得到完全支持。并且,华东师大文字中心以该系列数据库为根基的出土文献智能文字识别释读系统“文镜万象”系列正在开发中,其中“商周金文智能镜”日前已举行发布会,这一成果具有以下新功能——实现文字及其各种属性的系统识别,实现成篇文字材料的整体性识别,实现文字载体的特征性影像的识别。“商周金文智能镜”通过字形识别来打通商周金文各类数据关联对接,盘活数字化营造的商周金文大数据系统,推动商周金文研究迈向智能化时代。由上述研究成果可以看出,字体研发上的经验,对于促成标准字符集出台及出台后的科学使用,具有非常积极的意义。
作者:刘凌 刘志基(作者单位:华东师范大学中国文字研究与应用中心)
编辑:陈晨
责任编辑:任思蕴
*文汇独家稿件,转载请注明出处。
违法与不良信息举报电话:021-22898778
本网站文字、图片和视频作品,除特别说明外均为独家授权发布,转载请注明出处和原文链接。