



马上就要公布2021年诺贝尔奖了,时间就在今天傍晚。

其实此时此刻,最紧张的人也许不是各位年轻有为的科学家,而是——一位画家!
或许这么说有点奇怪,但如果你回忆一下往届诺奖颁布时各大媒体的新闻封面——


然后这些封面人物肖像其实是在诺奖公布的同一时刻发布,而且是艺术家用颜料手绘的,你会不会好奇,诺奖到底有没有提前公布?如果没有,这些肖像画又是什么时候、怎么画好的呢?
揭晓谜底之前,让我们先看看这位诺奖首席画家尼克拉斯·埃尔梅赫德(Niklas Elmehed)的帅照吧:

01比赛即将开始
艺术家尼克拉斯来自瑞典,自2012年以来,每年的10月上旬都将是他最紧张的作画时刻。想想我们印象中的肖像画吧:画家就坐在模特的对面,可以全面而又清晰的观察任何他需要的细节。
然而,尼克拉斯可没有这种观察的机会。一方面,大多数诺奖得主流传在外的照片很可能都过时几十年了,要不就是模糊到令人叹息;另一方面,为了保证诺奖得主的“获奖惊喜体验”——也就是在诺奖公布之前没有任何风吹草动可以让他们知道自己获奖了——尼可拉斯更不能唐突的去找诺奖得主询问照片。因此,这么多年以来,他都仅在诺奖公布前的数小时内悄悄得知获奖者的名字和照片,然后迅速而艺术的捕捉到一个个即将为世人瞩目的肖像。据说,他在40分钟内画出了一位文学奖得主的肖像。
“我必须一直表现得最好,”他说,“这就像一场比赛。”

02人物肖像绘画
尼克拉斯是怎么迅速而艺术的捕捉到人物肖像的呢?下面为大家介绍一下人物肖像绘画的“理论指导”:
【入门级】我们先勾勒出画像整体的轮廓——这相当于建立了一个整体坐标系;再确定眼睛、鼻子、嘴巴等面部器官或特征的相对位置关系;再刻画这些面部特征的具体形状;最后再交待一下明暗关系和细节刻画即可。

【进阶级】然而真正迅速准确地捕捉人物肖像的画家,一定还了解人脸的内部结构。人像可以看作这些肌肉舒张、收紧或扭曲最终在面部的投影。只有对这些头部肌肉形状和结构有着深刻的理解,在给人像变换表情、角度的时候,才能更加游刃有余、锦上添花。

好了好了,既然讲到这儿了,有必要继续探索一下,关于不会画画的我们是否还有机会提前知道诺奖得主的消息用技术(即计算机)捕捉人物肖像呢?
03动作捕捉技术
在人工智能时代来临之前,有一个行业已经迫不及待地开始发展动作捕捉技术(performance capture)了——那就是电影。有时候明明看的是动画片,为什么里面人物的动作表情自然的像真人一样?
因为,的确是真人表演为动画角色提供了模板。演员会穿上一套在关节处安有反射标记点(Marker)的动作捕捉服,并由几十上百台摄影机对其进行拍摄,每台摄影机发送一束光线到标记点。之后,光线再反射回摄影机镜头,以一系列黑底白点的形式被翻录到胶片上。这些白点反映了安装在演员身上的反射器的位置。最后,计算机会对多台摄影机同时捕捉的画面进行比较,再在此基础上建立3D动作模型。
如果把这些反射标记点戳在脸上,则可以在精准捕获人物表情。比如《加勒比海盗2》里的戴维·琼斯,给自己的轮廓贴了一圈blingbling的传感器——

以上的动作捕捉技术被称为“光学式运动捕捉”。它的精度高,而且表演者活动范围大,表演场地不受限制,但成本比较高。此外,还有机械式、声学式、电磁式捕捉。
机械式运动捕捉依靠机械装置来跟踪和测量运动。成本低、精度高,但机械结构对表演者的动作阻碍和限制也较大。
声学式运动捕捉由发送器、接收器和处理单元组成。通过测量声波从发送器到接收器的时间或相位差,可以计算接收器的位置和方向。这种装置成本低,但运动捕捉会有较大的延迟,精度不够高。
电磁式运动捕捉的组成部分与声学式相似。不过发射源在空间产生的不再是声波,而是按一定规律分布的电磁场。表演者身上的关键部位安装10~20个接受传感器,这些传感器接收到信号后,可以记录六维信息——不仅可以确定空间位置,还能确定运动方向。而且精度高、实时性好。但它对环境要求严格——表演场地附近不能有金属物品,否则造成的电磁场畸变会影响精度。
难道就没有一项技术,既能控制成本、又能达到精度要求,还能不受场地、动作的限制吗?
其实,以上技术和我们上一节“人物肖像绘画”中的【入门级】有相似之处——它们老老实实的记录了“表面现象”,却不用考虑人体、人脸的内部结构规律。然而,这些结构(包括人的骨骼、肌肉等)本身为标记点提供了额外的约束,包含了更多的信息。如果有技术可以考虑到这些信息,那么“直接识别人体特征的运动捕捉技术”便不再是梦想——
虚拟形象驱动。基于3D关键点和3D骨骼,通过普通摄像头实现的3D虚拟形象全身驱动。
于是,AI来了!
04人脸识别技术
无论什么方法技术,想要捕捉人脸,最关键的还是捕捉人脸“关键点”。人脸上的关键点就应该包含眉毛、眼睛、鼻子、嘴巴、脸部轮廓等的信息。
人脸关键点检测(也称“人脸对齐”)是指给定人脸图像,定位出人脸面部的关键区域位置。目前有很多种算法实现,这里仅介绍最基本的方法便于大家理解。其基本步骤为:人工标定训练集→对齐构建形状模型→搜索匹配。
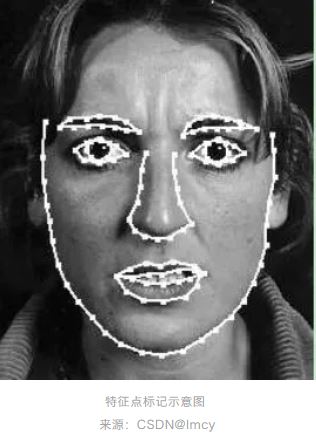
1、特征点标记
需要一组包含n个特征点的、N幅人脸图像(多个人的不同表情和姿态)作为训练数据。特征点标记在脸的外部轮廓和器官的边缘,各个标定点的顺序在训练集中的每张照片上需要一致。得到的特征点集,可以看做一个2n维的向量(n表示特征点数量)。
2、模型训练
首先需要“对齐”。对齐是指以某个形状为基准,对其它形状进行旋转、缩放和平移,使其尽可能的与基准形状接近的过程。然后对形状特征做PCA(主成分分析)处理,接着为每个关键点构建局部特征。
3、形状搜索
首先,计算眼睛(或者眼睛+嘴巴)的位置,做简单的缩放和旋转变化,对齐人脸;接着,在对齐后的各个点附近搜索,匹配每个局部关键点,得到初步形状;再用平均人脸(形状模型)修正匹配结果;迭代直到收敛。
通过以上步骤训练得到的模型,即可帮助我们获取人脸关键点的信息。这相当于学习了人脸的内部结构规律。在此基础上,可以轻松绘制出人脸的轮廓。此后,无论是磨皮还是美白,或者是人物动漫化,都相当于用不同的技法,对捕捉的人物肖像进行“艺术加工”。
磨皮主要是通过一个“保边滤波器”,对脸部非器官区域进行平滑处理。以其中的“导向滤波”为例,它根据图像纹理的复杂程度来调节相应的平滑程度。对于平坦区域近似于均值滤波,以处理其各种噪点;而在纹理复杂的区域则接近于原图,从而较完整的保存好轮廓区域的信息。
而美白,则是通过将肤色映射到理想的颜色范围来实现。输入任意的RGB颜色值(Rin, Gin, Bin),都可以在颜色查找表中找到对应的颜色值,从而内插出相应的转换结果(Rout, Gout, Bout)。如下图所示左边为基准颜色查找表,右边为调色后的肤色美白颜色查找表。
此外,脸部器官的美型就是基于人脸关键点,识别出了不同的器官,然后对各个器官实施不同的形变调整策略(眼睛变大、鼻翼变小等等)。而美妆处理也需要基于人脸关键点,对嘴唇、脸部等不同部位采取不同的渲染手段。
而人物形象动漫化,或迁移到其它风格,一般来说,基于机器学习算法(比如对抗神经网络GAN)可以很好的实现,感兴趣的朋友可以继续探索。
05预祝一切顺利
所以没错,技术的确可以捕捉到肖像、声音的基本特征。如果想要迅速准确地捕捉诺奖得主的肖像,不会画画,问题不大。
截至2019年,尼克拉斯已经画了近50幅肖像画了。在他看来,“在科学奖上,至少在我这几年里,他们更像是一类特殊的人。”他说,“我的意思是,所有这些人,以他们的智慧和他们所取得的成就,他们真的应该得到这个奖。还有一幅漂亮的肖像画。”所以他紧张疲惫,也倍感欣慰。
接下来又是诺奖前的绘画比赛!预祝一切顺利!
作者:蕉蕉的奇妙冒险
编辑:许琦敏
责任编辑:任荃
来源:中科院物理所
声明:转载此文是出于传递更多信息之目的。若有来源标注错误或侵犯了您的合法权益,请作者持权属证明与本网联系,我们将及时更正、删除,谢谢。