



如果说有一种解决问题的方法能跨域文化、种族和地域,那么除了抽签这种纯靠运气的方式,恐怕只剩下猜拳了。
人们普遍认可 “石头-剪刀-布” 三者之间的克制关系。“公平+随机” 的特性使其不仅是活跃气氛的小游戏,更能作为一种相对公平的解决问题的手段,广泛应用在解决分歧,决定顺序,或者确定归属的关键时刻。
更不用说,在谁洗碗、谁拖地、谁做饭之类的家务活上,猜拳自带的 “愿赌服输” 可以有效维系家庭和睦,堪称随叫随到的家庭关系调解员。
在大多数人的认知里,猜拳是随机事件,玩家获胜的概率应该是一样的且恒定在三分之一,但事实可能并非如此。
近日,浙江大学何赛灵教授的研究团队开发了一个基于马尔可夫链的 AI 模型,专门用来玩猜拳游戏。在和 52 名人类玩家分别大战 300 回合之后,AI 击败了 95% 的玩家。
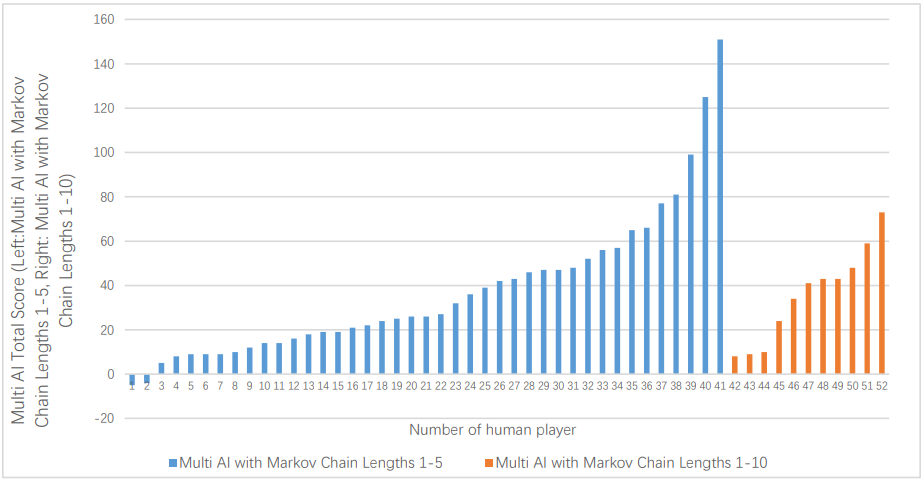
AI 模型净胜场数变化
对于人类玩家来说,规则是赢 +2 分,平 +1 分,输不得分。在与 AI 对战之前,参与者知道获胜会获得金钱奖励,总分越高,赢的钱越多。因此玩家故意放水或者随便乱选的概率极低。
即便如此,AI 仍然大胜人类。在最悬殊的一场较量中,AI 获得了 198 次胜利,55 次平手,仅输了 47 次,胜率超过人类对手 4 倍。全部 15600 回合详尽的原始博弈数据,在论文的补充资料中给出(详见参考文献)。
如果猜拳胜负真的是随机概率,那么从统计学的角度来讲,15600 场比赛下来,AI 获得如此大优势的概率非常低。
拥有“智囊团”的Multi-AI模型
本质上来看,猜拳属于博弈问题,其背后蕴藏着经典的纳什均衡,而每个个体的习惯、认知、策略和策略变化都会影响实际胜率。比如你和对手很熟悉,那么你可能知道他/她经常出布,因此可以多出剪刀来克制。
浙江大学何赛灵教授团队提出的 AI 模型就是利用了类似的方法,证明了猜拳真的存在针对不同个体的长期制胜策略,可以有效提高胜率。
这套 AI 模型基于 n-阶马尔可夫链设计,拥有记忆性,能够向前追溯最多 n 个历史状态并加以利用。
为了在实战中应对人类玩家的不同性格和策略,研究团队还发明了一套 Multi-AI 模型。
“建立对每个人都有效的单一模型很困难,因此我们决定将单个模型结合起来,使其能够区分和适应更多不同的竞争策略。” 研究人员在论文中解释称。
在与人类对战的第一套 Multi-AI 模型中,他们放入了 1-5 阶马尔可夫链,即 5 个独立的 AI 模型,分别参考之前 1-5 个动作。Multi-AI 会从整体上参考 5 个 AI 模型各自的决策,至于选择哪个,还要看它们最近 5 次的表现。
这里的 “最近 5 次” 被定义为一个超参数,名为 Focus length,可以视情况调整大小,实现进一步优化。在与人类对战的第二套 Multi-AI 模型中,该参数就被设为了 10。
打个比方,每一个 n 阶马尔可夫链模型就像是一位军师,各自有不同的决策标准。而 Multi-AI 模型就是司令,手底下有好多名军师组成的智囊团。做决策时,每个军师会提交自己的出拳建议,司令会根据他们过去几次(Focus Length)的表现,采纳综合分数最高的人的建议,以提高长期胜率。
如果人类玩家连续胜利,就会促使 Multi-AI 转向选择其他 AI 模型的更优解。如果人类玩家连续失败,大概率会转换策略,或者打破之前的出拳规律,这时 Multi-AI 也可以随之调整。
最终的社会实验结果反映出了这个想法的有效性。在 52 名志愿者中,只有不到 5 人击败了 AI。很多人都在最初 20-50 个回合里处于领先,但随后就被 AI 捕捉到了隐藏的行为模式,饮恨败北。
那些击败 AI 的人,胜率也只是稍微高出一些,并未拉开太大差距。
6 年前被质疑的研究
值得一提的是,在开发 AI 模型背后的算法时,研究团队阅读了 6 年前另一个浙大团队的研究成果,但使用了另一种不同的博弈策略。
相较于之前对于所有玩家数据整体以统计学的方式进行研究,这里的 Multi-AI 模型更强调针对不同玩家之间的个性差异、出拳策略,来及时的进行调控,选取当下最适宜的博弈策略。
2014 年 5 月,很多媒体都报道了一项以 “石头剪刀布” 游戏为对象的科研成果。
这项研究课题原本是 “可控实验社会博弈系统中一些非平衡统计物理问题”,但媒体和舆论关注的重点大多是 “如何提高猜拳胜率”,因此还被质疑是浪费经费。
其实不然。这项研究还被《麻省理工科技评论》评为 2014 年最佳成果(预印本)之一。
编辑:王星
责任编辑:唐闻佳
图文来源:Deeptech深科技
声明:转载此文是出于传递更多信息之目的。若有来源标注错误或侵犯了您的合法权益,请作者持权属证明与本网联系,我们将及时更正、删除,谢谢。