




我们对于数据使用方式的范式正在改变。比如对于一头豹子的图像处理,过去是对于单一物体的单一标注,如今标注范式变得多维:包括物体、环境、颜色、数量等等,要从视觉和自然语言的维度来理解万物。数据使用方式的新范式,正在导致数据从单模态独立使用到多模态统一使用。
在需要同时解决多项任务的高需求下,近年来,大模型预训练正表现出前所未有的理解与创造能力,成为一大热门。在外界看来,大模型预训练的出现,打破了传统AI只能处理单一任务的限制,使得人类离通用人工智能的目标近了一步。
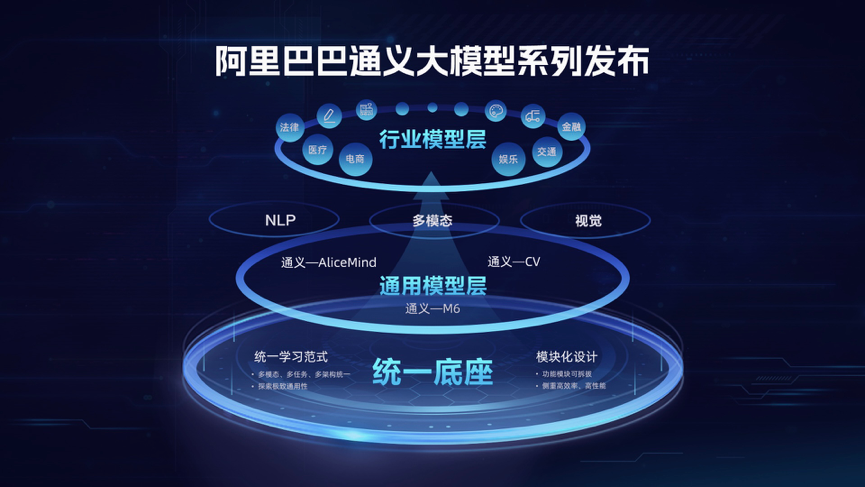
在阿里巴巴达摩院今天举行的WAIC“大规模预训练模型”主题论坛上,达摩院副院长周靖人发布阿里巴巴最新“通义”大模型系列,并宣布相关核心模型向全球开发者开源开放。面向大模型通用性与易用性仍欠缺的难题,通义打造了业界首个AI统一底座,并构建了大小模型协同的层次化人工智能体系,将为AI从感知智能迈向知识驱动的认知智能提供先进基础设施。
资料显示,通义大模型从2020年1月起步研发,包括训练、推理、任务、应用等多个方向,目前已经成为超大规模多模态预训练模型和系统,在超大模型、低碳训练技术、平台化服务、落地应用等方面实现突破,引领了中文大模型的发展。尤其引发关注的是,达摩院团队使用512卡V100 GPU即实现10万亿参数大模型M6,同等参数规模能耗仅为此前业界标杆的1%,极大降低了大模型训练门槛。
达摩院副院长周靖人介绍,为了让大模型更加“融会贯通”,达摩院在国内率先构建了AI统一底座,在业界首次实现模态表示、任务表示、模型结构的统一。通义统一底座中M6-OFA模型,作为单一模型,在不引入新增结构的情况下,可同时处理图像描述、视觉定位、文生图、视觉蕴含、文档摘要等10余项单模态和跨模态任务,且效果达到国际领先水平。这一突破最大程度打通了AI的感官,受到学界和工业界广泛关注。近期M6-OFA完成升级后,可处理超过30种跨模态任务。

“大模型模仿了人类构建认知的过程,这是当下我们面临的重要机遇。通过融合AI在语言、语音、视觉等不同模态和领域的知识体系,我们期望多模态大模型能成为下一代人工智能算法的基石,让AI从只能使用‘单一感官’到‘五官全开’,且能调用储备丰富知识的大脑来理解世界和思考,最终实现接近人类水平的认知智能。”周靖人表示。
同时,以统一底座为基础,达摩院构建了层次化的模型体系,其中通用模型层覆盖自然语言处理、多模态、计算机视觉,专业模型层深入电商、医疗、法律、金融、娱乐等行业。通用与专业领域大小模型协同,让通义大模型系列可兼顾性能最优化与低成本落地。为加快大模型规模化应用,达摩院还研发了超大模型落地关键技术S4框架,百亿参数大模型在压缩率达99%的情况下多任务精度可接近无损。
通过部署超大模型及轻量化版本,阿里巴巴通义大模型系列已在超过200个场景中提供服务,实现了2%~10%的应用效果提升。典型使用场景包括电商跨模态搜索、AI辅助设计、开放域人机对话、法律文书学习、医疗文本理解等。
作者:徐晶卉
编辑:薄小波
责任编辑:戎兵
*文汇独家稿件,转载请注明出处。