




你在键盘上输入开头:“这是一个关于小狗 Boo 的故事。”
片刻之后,AI 为你返回一个完整的叙事:“这是一个关于小狗 Boo 的故事。Boo 是一只拉布拉多犬,它爱人类胜过一切。一年多前,弗吉尼亚州阿灵顿市的狗狗救援行动救助了 Boo,它是一只被遗弃的小狗 ( 现在 2 岁 )。Boo 的故事令人动容。”
这不是假新闻,而是 OpenAI 开发出来的最新语言模型所能实现的效果。
在此前的 DOTA 2 AI 惨败后,这家马斯克倡导成立(现已退出董事会)的 AI 机构在今天发布了其自然语言处理(NLP)模型——GPT-2。GPT-2 最大的亮点是可以生成给定单词或句子的连贯文本,而且在一系列 NLP 测试中实现最佳 (或接近最佳) 性能。我们可以简单地将其理解为一款“洋葱新闻 AI”,但它的价值远不止于此。自然语言处理专家、Salesforce 首席科学家 Richard Socher 对《麻省理工科技评论》表示,OpenAI 这次的工作展示了一个更通用的语言学习系统,这些通用学习系统代表着未来。
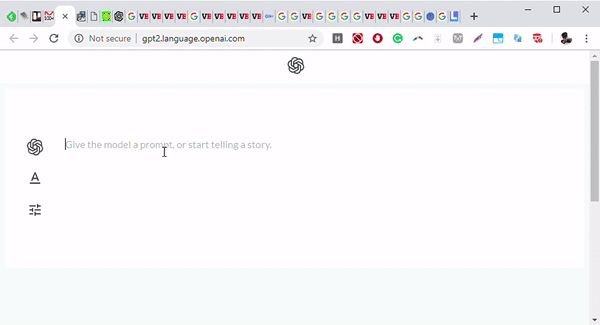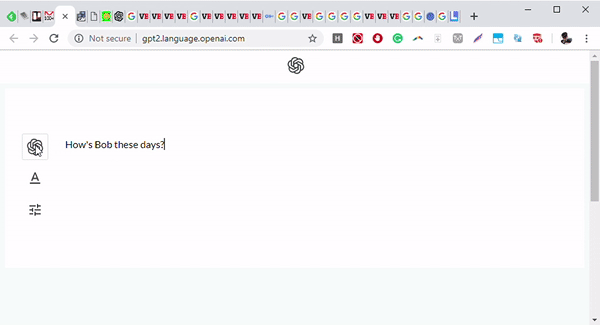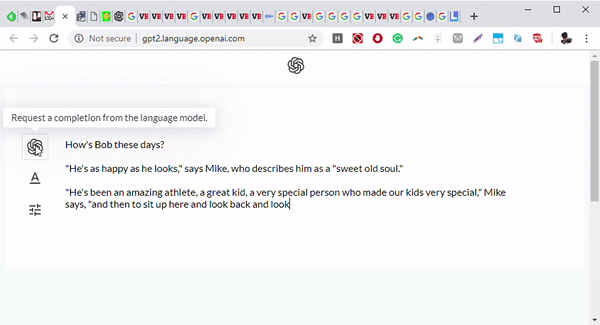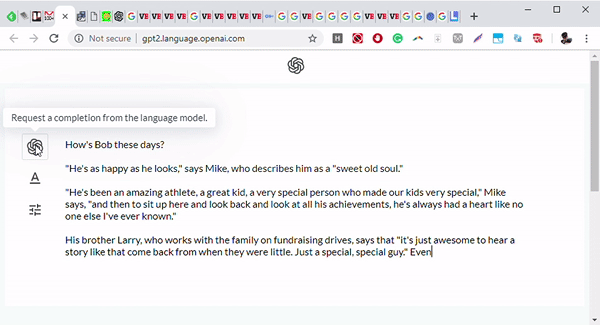
▲图丨GPT-2 根据输入“Bob最近怎样”输出了一个完整的短故事,目前测试只面向研究人员开放(来源:OpenAI)
人类语言的力量已经不必多说,但也正是因为其强大,构建真正理解人类语言的 AI 的过程也异常艰辛。
目前,我们已经迎来几项标志性成果,例如谷歌的 BERT,例如谷歌的 BERT,它利用预训练好的模型,可以在几个小时内在单个显卡上训练最先进 NLP 模型,而 Facebook 的 PyText,则可以每天为社交网络的应用程序和服务生成超过 10 亿个预测。这些成果已经推动了 NLP 相关的研究。但是,在没有人工制作的语法规则和精心标记的数据集辅助的情况下,AI 目前还难以实现自然“说话”。
这也是为什么 OpenAI 这次的研究非常值得关注的原因。

▲图丨 GPT-2 的表现(来源:OpenAI)
先前的研究表明,无监督学习从非分类、无注释的数据中学习可以用于从通用模型到特定的语言任务。OpenAI 认为,GPT-2 的诞生表明,足够大的语言模型可以在不需要特定领域数据集或修改的情况下学习 NLP 任务。
这些模型核心的神经网络由神经元组成,这些神经元仿照生物神经元松散建模实现数学功能。这些神经元与层层排列的能传递信号给其他神经元的“突触”相连。数据信号从一层传递到另一层,然后通过调整每个连接的突触强度 (权重) 来缓慢地“调整”神经网络。随着时间的推移,神经网络就能从数据集中提取特征并识别样本之间的趋势,最终学会做出预测。
GPT-2 基于 OpenAI 先前的研究成果 GPT。有意思的是,2018 年轰动 NLP 领域的谷歌 BERT 模型,其很多思想也与 GPT 这个“前辈”有关系。GPT-2 继承了 GPT 的一些特性,在一定程度上同样依赖 Transformers 实现其效果。Transformers 是一种相对新颖的神经结构,于 2017 年由 Google Brain 团队在论文《Attention Is All You Need》中引入。
Transformers 为这一复杂过程增添了“自注意力机制”(self-attention)。神经元群以不同的速率传递信号,并将信号以某种智能的方式传送到下一层。这种结合 40GB、800 万条网络评论、帖子和文章相当于 100 亿个单词的架构调整,可以让 OpenAI 模型查询之前经验的相关信息, 而且十分简单快速。
OpenAI 数据解决方案和语言研究主管 Alec Radford 在一次电话简报中告诉表示:“一些人工智能模型强行将上下文的所有信息汇总或压缩成一个固定长度,这是一项非常困难的任务。这与以自我关注为基础的模型截然相反,自我关注模型将所有不同的单词放在上下文中,并学习如何查询之前信息的功能。如果模型看到像‘先生’或‘太太’这样的单词,就可以学习如何查看文档和前面所有的单词,并判断出哪一个名字可能跟在这一称谓后面。”
已有的测试显示,输入“敏捷的棕色狐狸跃过了一只狗”,模型处理后写到:“敏捷的棕色狐狸跃过了一只狗。这只狗真懒!’这有什么了不起的?’我问到,棕色狐狸笑了,狗也舔了舔嘴唇。’我不知道。但你不必知道,因为一旦你懂了……’我懂了,我说。
输入“John 今天早上醒来感觉很饿”,模型返回“John 今天早上醒来感觉很饿。这是因为这家餐厅一般会营业到 7 月份,但由于感恩节假期,餐厅有些窗口关门了。John 的晚饭只有一份拌上奶酪和调味品的新鲜蔬菜沙拉。土豆是棕色的,沙拉很有味道。”
而在另一类 Amazon 模型的测试中(用于指定产品类别、产品名称、评论得分和评论摘要),输入“一个很棒的手机”,随后,产品切换设置为“手机及配件”,评论等级设置为“5”。
它生成的是:“这款手机太棒了! 我是 2013 年 7 月买的。我还会购买第二部的。它能通过麦克风发短信、播放音乐和与他人交谈,而且音质很好。不过耳塞戴上几个小时后,耳朵有点不舒服。我遇到的唯一问题是电池的寿命。这只是技术上的问题,手机使用一段时间后就会耗电严重。除此之外,我喜欢这款手机。这是我用过的最好的手机。这是一款很棒的手机。机壳的触感很好,但是很容易变脏。如果你的手机上有摄像头,你可以用它拍照。我上传了自从我有了手机后的照片。
不得不说上面这个评论已经和人类用户给出的评论非常接近了,无论是表达还是信息组织的逻辑。

▲来源:OpenAI
对此,OpenAI 表示,模型在第一次运行时,大约有一半的时间会生成“有趣的”和“连贯的”文本。Radford 说:“。Radford 说:“。Radford 说:“它试图在尽可能少的信息下预测下一个单词。你能给出的上下文越多,它就会表现得越好。”
而在 zero-shot 任务迁移的实验中,模型没有事先在任何特定于测试的数据集上进行训练,OpenAI 表示,该模型的四种语言系统中最大的语言系统 OpenAI gps -2 在八个基准测试中,成功地在七个测试中获得了最佳分数,包括 LAMBADA 测试 (模型在文本中建模长期依赖关系能力的测试)、Winograd 模式挑战 (解决文本中歧义的能力的测试) 和 Penn Treebank(包含数百万个标记了部分的文本的演讲集合)。

▲来源:OpenAI
它还显示出无监督学习任务的执行能力。在回答问题的测试中,它在获得上下文的情况下的准确率达到 83.4%。

▲图丨问答表现(来源:OpenAI)
“它能够利用更大的模型和更多的数据成为一个‘多面手’,一般的语言预测任务都能执行得很好。在一些非常有针对性的任务中,如汇总或翻译,它也展示了初步的潜力。这太令人兴奋了,因为我们没有明确针对这些任务进行训练。”Radford 说。尽管如此,Radford 和 OpenAI 技术人员杰弗里·吴 (Jeffrey Wu) 也承认,这还远远不是自然语言处理的终点:这些模型一次只能看到一页以下的数据,而且在推理时逻辑并不完全一致——有时会有很夸张的数字,或者以一种荒谬的方式跑题了。OpenAI 团队未来将继续改进这些问题。
与以往的做法不同的是,这一次,OpenAI 既不发布用于培训 NLP 模型的数据集,也不发布相关的语言模型或培训代码。它认为,发布这些信息可能会为滥用打开大门。
OpenAI 在博客中写道:“同样的工具,一个艺术家可以利用来帮助他们写一个短篇小说的故事,可以用来制作关于某个公司的财务新闻,也可以在知名网站上创建虚假评论,甚至是强化政治性舆论影响…基于这些考虑,我们本着负责任的态度发布这个模型,希望贡献或者得到沟负责任的讨论,从而使记者、决策者等其他重要利益相关者也能够理解和验证我们所做的事情。”OpenAI 所做的这项工作,其实也呼应了当下全球信息传播中的一个重要议题——可以用来生成误导性内容的 AI 系统正受到越来越多的审查。2018 年 9 月,美国国会议员就要求情报机构就 deepfake(AI 视频造假)对国家安全的潜在影响提交报告。在 2018 年末的一次国会听证会上,国会议员们在与 Facebook 首席运营官谢丽尔·桑德伯格 (Sheryl Sandberg) 和 Twitter 首席执行官杰克·多尔西 (Jack Dorsey) 交谈时,也表达了对操纵 deepfake 的潜在影响的担忧。我们不排除,甚至可以肯定的说,未来 OpenAI 最新的这款语言模型或者其他类似的模型一定会被用来生成不真实或误导性的故事。数据显示,2018 年 3 月,半数美国人表示在新闻网站上看到了故意误导的文章。有机构预测,如果目前的趋势持续下去,到 2022 年,大多数发达国家的人每天将看到更多的虚假信息,而非真实信息。因此, OpenAI 的顾虑是完全合理的。
现在也有不少团队正在开发能够与假新闻 AI 对抗的 AI。例如,麻省理工学院的研究人员就在试图用自动化工具来对抗人工和 AI 编写的假新闻,这些工具可以判断消息来源的准确性或政治偏见。但是,一些专家不相信这样的做法能取得多显著的效果。
卡内基梅隆大学机器人研究所 (Carnegie Mellon University Robotics Institute) 的科学家迪安·波默洛 (Dean Pomerleau) 参与组织了“假新闻挑战赛”(Fake News Challenge),这是一项众包偏见检测算法的竞赛。他在一次采访中透露,,这是一项众包偏见检测算法的竞赛。他在一次采访中透露,,这是一项众包偏见检测算法的竞赛。“实际上,我们一开始就有一个更宏伟的目标,那就是创建一个能够回答‘这是假新闻吗,是还是不是?’这个问题的系统。”“他说。“但我们很快意识到机器学习无法胜任这项任务。”

▲来源:麻省理工科技评论
但也不用如此消极。很明显,各国在政策领域还有很多改善的空间。OpenAI 也希望通过这次研究,不仅能展示它在 NLP 领域取得的成果,还能在研究人员和监管机构之间引发辩论。
OpenAI 说:“我们在组织内部的初步共识的指导下得出一个结论,即这个模型在质量上优于以往,而且被滥用的可能性比我们参与的此前项目更高。我们最终希望创建一个由人工智能从业者组成的全球社区,让他们思考特定类型信息发布的风险。”
不过,除了对假新闻的担忧以外,这次的研究还继续佐证了目前深度学习研究领域的一个“法则”(甚至可以认为是“诅咒”):,除了对假新闻的担忧以外,这次的研究还继续佐证了目前深度学习研究领域的一个“法则”(甚至可以认为是“诅咒”):,除了对假新闻的担忧以外,这次的研究还继续佐证了目前深度学习研究领域的一个“法则”(甚至可以认为是“诅咒”):数据、计算资源和人才三大关键因素缺一不可,突破性成果越来越可能只有大机构大企业才能支撑完成。无论是去年 3 亿参数的 BERT,还是现在动用了 15 亿参数、每小时训练价格高达 2048 美元的 GPT-2 ,都没有避开。
作者:黄珊 李亚山
编辑:顾军
责任编辑:任荃
来源:综合自DeepTech深科技、微博等
违法与不良信息举报电话:021-22898778
本网站文字、图片和视频作品,除特别说明外均为独家授权发布,转载请注明出处和原文链接。